Amazon ElastiCache
คล้ายกับที่ Amazon RDS ให้บริการฐานข้อมูลแบบ relational แบบ managed ElastiCache ให้บริการ Redis หรือ Memcached แบบ managed ซึ่งเป็นเทคโนโลยีสำหรับ Caching
Cache คืออะไร?
Cache เป็น ฐานข้อมูลในหน่วยความจำ (in-memory) ที่มี ประสิทธิภาพสูงและ latency ต่ำมาก
- ช่วยลดภาระบนฐานข้อมูลสำหรับ workload ที่อ่านข้อมูลบ่อย (read-intensive)
- Cache จะเก็บผลลัพธ์ของ query ที่พบบ่อย ทำให้ ฐานข้อมูลไม่ต้องถูก query ทุกครั้ง
- การใช้ cache ยังช่วยให้แอปพลิเคชันเป็น stateless โดยเก็บสถานะของแอปใน ElastiCache
เหมือนกับ RDS, AWS จะดูแลงานบำรุงรักษาให้กับ ElastiCache เช่น
- การจัดการระบบปฏิบัติการ
- การ patch
- การปรับแต่งและตั้งค่า
- การมอนิเตอร์
- การกู้คืนเมื่อเกิดความล้มเหลว
- การ backup
แต่การใช้ ElastiCache ต้องมี การปรับโค้ดแอปพลิเคชัน แอปต้อง query cache ก่อนหรือหลัง query database ไม่สามารถเปิดใช้งานได้ทันทีโดยไม่ปรับโค้ด
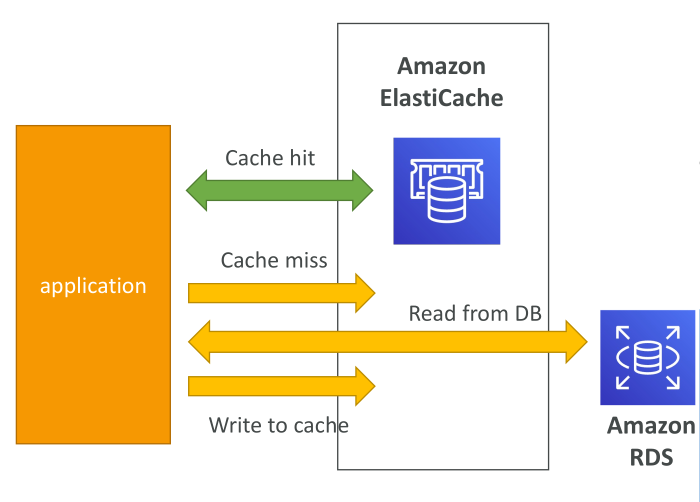
ตัวอย่างสถาปัตยกรรม ElastiCache
สมมติสถาปัตยกรรมมี:
- ElastiCache
- RDS database
- แอปพลิเคชัน
-
แอปพลิเคชัน query ElastiCache ก่อน
-
หากพบข้อมูล → cache hit → ดึงผลลัพธ์จาก cache โดยไม่ต้อง query database
-
หากไม่พบข้อมูล → cache miss → query database
- จากนั้นเก็บผลลัพธ์กลับเข้า cache เพื่อให้ query ครั้งต่อไปเป็น cache hit
ข้อควรระวัง: ต้องมี cache invalidation strategy เพื่อให้ข้อมูลที่ cache เป็นข้อมูลล่าสุด
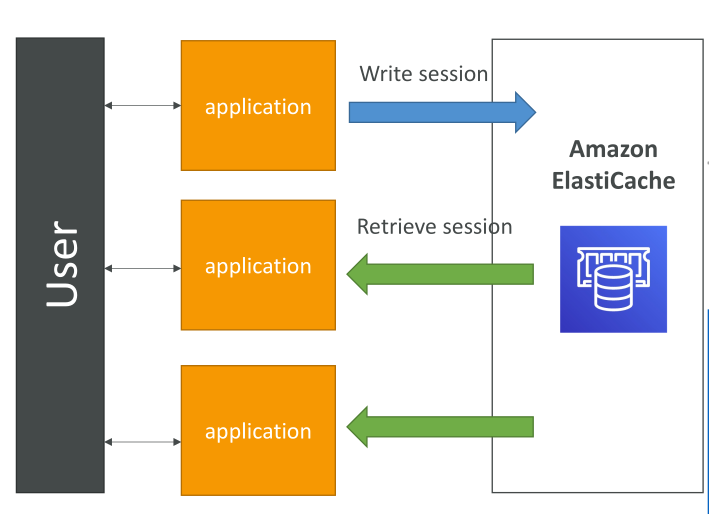
การใช้ ElastiCache กับ User Sessions
- เก็บ session ของผู้ใช้ ใน ElastiCache → แอปเป็น stateless
- เมื่อผู้ใช้ login → session data เขียนลงใน ElastiCache
- หากผู้ใช้ถูก redirect ไปยัง instance ของแอปอีกตัว → ดึง session จาก ElastiCache → ไม่ต้อง login ใหม่
เปรียบเทียบ Redis และ Memcached
Redis
- รองรับ multi-availability zones และ auto-failover
- สร้าง read replicas เพื่อ scale read และเพิ่มความพร้อมใช้งาน
- รองรับ data durability ผ่าน Append Only File (AOF)
- มี backup และ restore ในเวอร์ชัน open-source
- รองรับ sets และ sorted sets → ใช้กับ features เช่น leaderboard
- แนวคิด: Redis คือ node ที่ replicate ไปยัง node อื่น → มี redundancy และ availability
Memcached
- ใช้หลาย node sharding เพื่อแบ่ง partition ของข้อมูล
- ไม่มี replication และ high availability
- serverless version มี backup/restore แต่ self-managed version บน ElastiCache ไม่มี
- ใช้ multi-threaded architecture → เพิ่มประสิทธิภาพ
- แนวคิด: Memcached nodes แบ่งข้อมูลไปยังหลาย node ทำงานร่วมกันเพื่อ partition และแชร์ข้อมูล
สำหรับการสอบ อาจไม่เน้นการเลือก Redis หรือ Memcached แต่ควรเข้าใจความแตกต่างและกรณีการใช้งาน
สรุป
- Amazon ElastiCache ให้บริการ Redis และ Memcached แบบ managed → ลดภาระ read-intensive workload ของฐานข้อมูล
- Cache เป็น in-memory database → ประสิทธิภาพสูงและ latency ต่ำ → ช่วยทำแอป stateless
- ใช้ cache hit/miss strategy เพื่อ optimize การดึงข้อมูล แต่ต้องมี cache invalidation
- Redis: multi-AZ, replication, persistence, advanced data structures
- Memcached: sharding, multi-threading แต่ไม่มี replication และ high availability

กลยุทธ์การใช้ Caching
แนะนำกลยุทธ์การใช้ Cache
มาลงลึกเกี่ยวกับ กลยุทธ์การใช้ cache ที่สามารถนำไปใช้กับแอปพลิเคชัน และสิ่งที่ควรพิจารณา
-
คำถามสำคัญ: การเก็บข้อมูลใน cache ปลอดภัยไหม?
- ส่วนใหญ่ปลอดภัย แต่บางครั้งข้อมูลอาจไม่เป็นปัจจุบัน → เกิด eventual consistency
- ไม่ใช่ข้อมูลทุกประเภทเหมาะกับการ cache ต้องตรวจสอบว่าเหมาะสมกับข้อมูลของคุณ
-
คำถามที่สอง: การใช้ cache มีประสิทธิภาพไหม?
- ถ้าข้อมูลเปลี่ยนช้าและมีบาง key ถูกเข้าถึงบ่อย → caching มีประสิทธิภาพสูง
- ถ้าข้อมูลเปลี่ยนเร็วมากและต้องการเข้าถึงทุก key → caching อาจไม่คุ้มค่า
-
โครงสร้างข้อมูล:
- ข้อมูลควรเหมาะสมกับ caching เช่น key-value pairs หรือ ผลลัพธ์ที่ aggregate
- การ cache คือการประหยัดเวลาและเพิ่มความเร็วในการเข้าถึง
การเลือก Caching Design Pattern ที่เหมาะสม
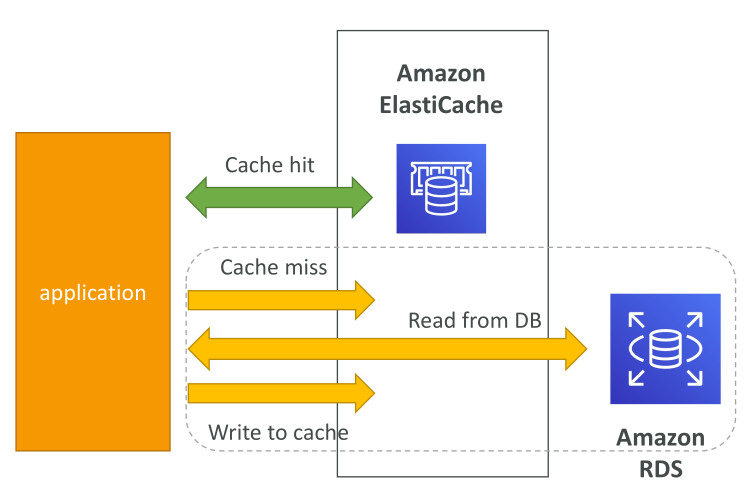
1. Lazy Loading (Cache-Aside หรือ Lazy Population)
-
ประกอบด้วย แอปพลิเคชัน, ElastiCache (Redis/Memcached) และ RDS
-
การทำงาน:
- แอป query cache ก่อน
- Cache hit → คืนข้อมูลทันที
- Cache miss → query database → เก็บผลลัพธ์ลง cache → คืนข้อมูล
-
ข้อดี:
- cache เฉพาะข้อมูลที่ถูกเรียก → ประหยัดพื้นที่
- หาก cache ถูกล้างหรือ node ล้ม → ระบบยังทำงานได้เพียง latency เพิ่มขึ้น
-
ข้อเสีย:
- Cache miss ทำให้เกิด 3 network calls → latency เพิ่มขึ้น
- อาจเกิดข้อมูลเก่า (stale data) หาก database อัพเดตไม่ทัน cache
ตัวอย่าง Lazy Loading ใน Python
def get_user(user_id):
record = cache.get(user_id)
if record is None:
record = db.query("SELECT * FROM users WHERE id = %s", user_id)
cache.set(user_id, record)
return record
2. Write Through Caching
-
อัพเดต cache ทุกครั้งที่ database ถูกอัพเดต
-
การทำงาน:
- แอปเขียนข้อมูลไป database → เขียนข้อมูลเดียวกันไป cache
-
ข้อดี: cache จะไม่ stale
-
ข้อเสีย: write penalty เพราะต้องเขียน 2 ที่ (database + cache)
-
สามารถรวมกับ Lazy Loading → cache miss trigger load จาก database
ตัวอย่าง Write Through ใน Python
def save_user(user_id, user_data):
record = db.query_update("UPDATE users SET data = %s WHERE id = %s", user_data, user_id)
cache.set(user_id, record)
return record
Cache Evictions และ Time-to-Live (TTL)
-
Cache มีขนาดจำกัด → ต้องมีนโยบาย eviction
-
Eviction: ลบข้อมูลเมื่อ cache เต็ม
- นโยบาย LRU (Least Recently Used) → ลบ item ที่ไม่ได้เข้าถึงล่าสุด
-
TTL (Time-to-Live) → กำหนดเวลาหมดอายุของข้อมูลใน cache
- ใช้ได้กับข้อมูลเช่น leaderboard, comments, activity streams
- TTL ตั้งได้ตั้งแต่ วินาทีถึงหลายวัน
-
หากเกิด eviction บ่อย → พิจารณาขยาย cache size
แนวคิดสุดท้ายเกี่ยวกับ Caching
- Lazy Loading → ใช้งานง่าย → เพิ่มประสิทธิภาพ read performance
- Write Through → ป้องกันข้อมูล stale → ใช้หลังจาก Lazy Loading
- TTL → ดีต่อการจัดการความสดของข้อมูล
- เฉพาะ cache ข้อมูลที่เหมาะสม เช่น user profiles, blogs
- หลีกเลี่ยง cache ข้อมูล sensitive หรือเปลี่ยนเร็ว เช่น ราคา, balance
คำกล่าวโด่งดัง: "There are two hard things in Computer Science: cache invalidation and naming things." → Caching เป็นเรื่องซับซ้อน แต่ต้องเข้าใจสำหรับการสอบ
Amazon MemoryDB for Redis
Amazon MemoryDB for Redis เป็นบริการ ฐานข้อมูล in-memory ที่เข้ากันได้กับ Redis และรองรับความทนทานของข้อมูล (durable)
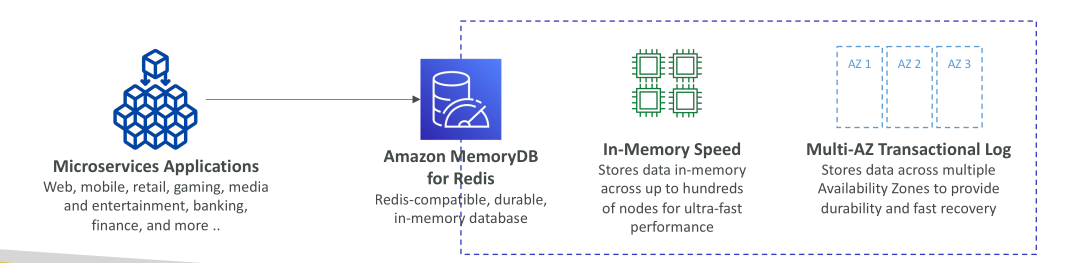
ความแตกต่างระหว่าง Redis กับ MemoryDB for Redis
-
Redis: ออกแบบมาเพื่อใช้เป็น cache เป็นหลัก มีความทนทานของข้อมูลบางส่วน
-
MemoryDB for Redis: ออกแบบเป็น ฐานข้อมูลเต็มรูปแบบ พร้อม API ที่เข้ากับ Redis
- หมายความว่า MemoryDB ให้ การจัดเก็บข้อมูลที่ทนทาน พร้อมกับ ประสิทธิภาพที่สูงมาก
-
ประสิทธิภาพ: MemoryDB สามารถจัดการคำขอได้มากกว่า 160 ล้านคำขอต่อวินาที
-
ข้อมูลถูกเก็บ ในหน่วยความจำ (in-memory) แต่ยังรับประกันความทนทานผ่าน Multi-AZ transaction logs
ความสามารถในการขยายและกรณีการใช้งาน
-
MemoryDB ขยายได้ตั้งแต่ ไม่กี่สิบ GB จนถึงหลายร้อย TB
-
กรณีการใช้งานที่เหมาะสม:
- แอปเว็บและมือถือ
- เกมออนไลน์
- การสตรีมสื่อ
- สถานการณ์ที่ microservices ต้องการ ฐานข้อมูล in-memory ที่เร็วและเข้ากับ Redis
-
การใช้ MemoryDB for Redis ให้ ความเร็วสูงแบบ in-memory พร้อม transaction log แบบ Multi-AZ
- ทำให้สามารถ กู้คืนข้อมูลได้อย่างรวดเร็ว และ ข้อมูลมีความทนทาน